
이번엔 개,고양이를 구분하는 인공지능을 직접 구현해보자.
https://www.tensorflow.org/datasets/catalog/cats_vs_dogs
고양이 대 개 | TensorFlow Datasets
TensorFlow.js의 새로운 온라인 과정에서 웹 ML을 통해 0에서 영웅으로 거듭나십시오. 지금 등록하세요 이 페이지는 Cloud Translation API를 통해 번역되었습니다. Switch to English 고양이 대 개 고양이와 개
www.tensorflow.org
Dataset은 위에서 가져왔다.
import os
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfds
tfds.disable_progress_bar()tensorflow_datasets 라이브러리에서 가져올 수 있다!
import os
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
IMG_SIZE = 160 # All images will be resized to 160x160
def format_example(image, label):
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE))
return image, label
(raw_train, raw_validation, raw_test), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
type(raw_train)
raw_train
raw_validation
raw_test
get_label_name = metadata.features['label'].int2str
get_label_name
for image, label in raw_train.take(2):
plt.figure()
plt.imshow(image)
plt.title(get_label_name(label))
plt.show()
코랩으로 실행하는걸 추천한다..
먼저 tesorflow_datasets 라이브러리를 통해 받아온 이미지를 가공하고
label을 해준다. 예를 들어 개는 1, 고양이는 0으로 하는것처럼 해준다. CNN을 이용하기 위해서는 사진의 크기가 고정되어야 하기 때문에
train = raw_train.map(format_example)
validation = raw_validation.map(format_example)
test = raw_test.map(format_example)
위와 같이 형태를 적합하게 맞추어 준다.
BATCH_SIZE = 32
SHUFFLE_BUFFER_SIZE = 1000
train_batches = train.shuffle(SHUFFLE_BUFFER_SIZE).batch(BATCH_SIZE)
validation_batches = validation.batch(BATCH_SIZE)
test_batches = test.batch(BATCH_SIZE)
for image_batch, label_batch in train_batches.take(1):
pass
print(image_batch.shape)그 후 batch 사이즈를 정해준다.

잘나왔는지 출력을 한번 해보자.
우리는 VGG16 모델을 통해서 구현할 것인데 이를 직접구현하면 어렵고 코드도 많이 작성해야 하지만.. 텐서플로우에서는 이또한 지원해준다!
IMG_SHAPE = (IMG_SIZE, IMG_SIZE, 3)
# Create the base model from the pre-trained model VGG16
base_model = tf.keras.applications.VGG16(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')base_model로 위처럼 저장해준다.
feature_batch = base_model(image_batch)
print(feature_batch.shape)
base_model.trainable = False
이미지 배치에 의한 feature_batch도 한번 보자.

base_model.trainable = Falsetrainable 을 false로 둬서 앞 글에서 했던 Fine-Tuning부분에서 Convolutional Base를 비워두는것으로 설정하였다!
print(base_model.summary())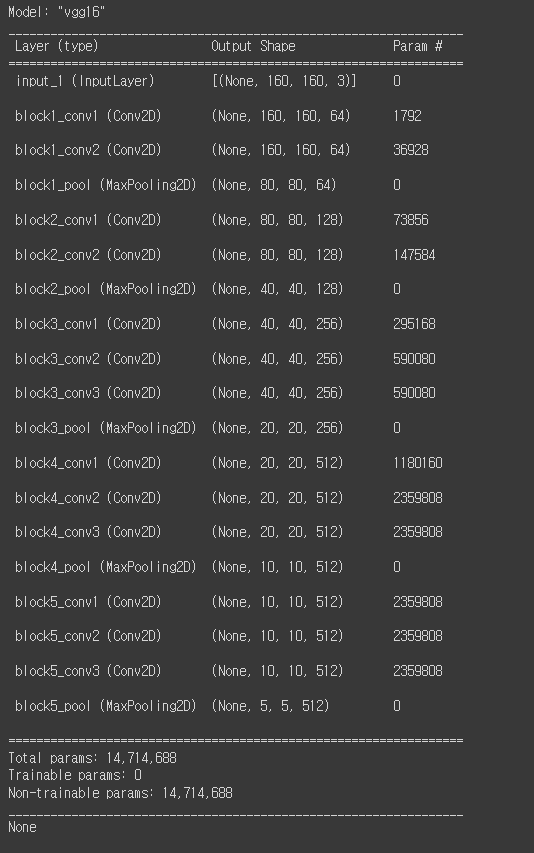
자, 우리가 설정한 vgg16의 개요는 위처럼 설정되었다.
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)GlobalAveragePooling을 통해서 5 * 5 feature맵 하나가 하나의 스칼라값으로 나와서
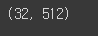
위와같이 나오게 된다.
prediction_layer = tf.keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
model = tf.keras.Sequential([
base_model,
global_average_layer,
prediction_layer
])그후 1이면개, 0이면 고양이인걸 생각해서 이분적 prediction_layer로 설정해서 model에 붙여주는 작업이 필요하다.
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()그후 learning_rate까지 설정하고 요약을 한번 더 보면
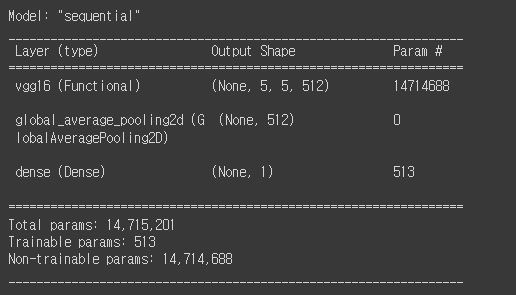
dense 레이어만 학습대상으로 가진것을 알 수 있다.
initial_epochs = 10
validation_steps = 20
loss0, accuracy0 = model.evaluate(validation_batches, steps = validation_steps)
print("initial loss: {:.2f}".format(loss0))
print("initial accuracy: {:.2f}".format(accuracy0))현재 에폭과 스탭을 정해준 다음에 학습이 안된 상태에서 loss값과 정확도를 보면
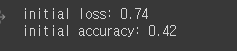
낮은값을 가진것을 알 수 있다. 그러면 학습을 시켜보자.
history = model.fit(train_batches,
epochs=initial_epochs,
validation_data=validation_batches)
print(type(history.history))
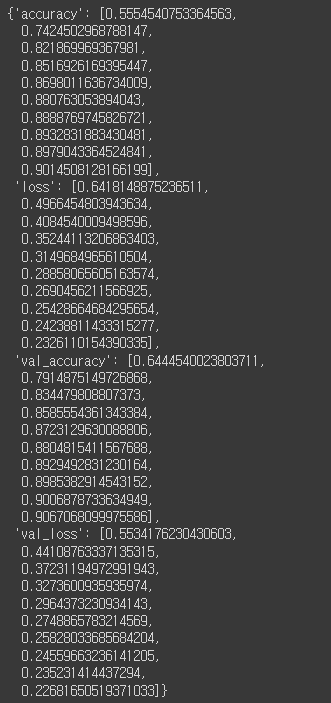
history.history
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
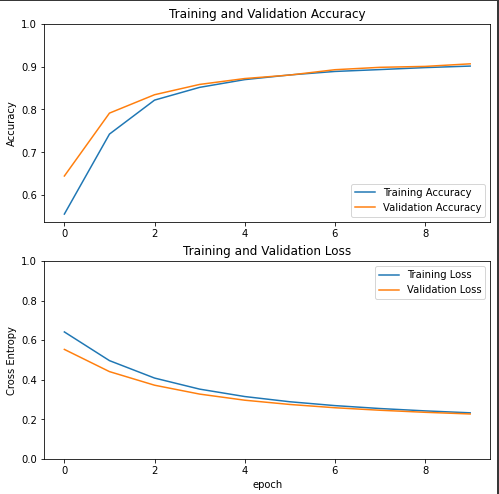
시각적으로도 잘 학습된걸 볼 수 있다.
그렇다면 앞에 5개 Convolution Layer 부분까지 Fine-Tuning을 하면 어떻게 나올까?
len(base_model.layers)
# set fine-tuning layers
base_model.trainable = True
set_trainable = False
for layer in base_model.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.RMSprop(lr=base_learning_rate/10),
metrics=['accuracy'])
model.summary()
print(len(model.trainable_variables))
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_batches,
epochs=total_epochs,
initial_epoch = history.epoch[-1],
validation_data=validation_batches)
history_fine.history
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.8, 1])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0, 1.0])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()코드에서 block5_convol1 이 오면 false로 설정되었던 trainable을 조정함을 볼 수 있다!
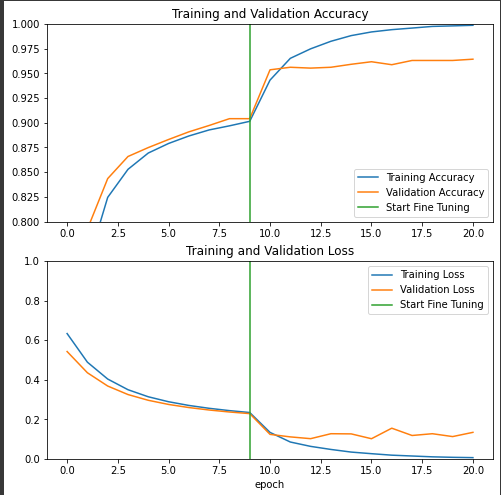
시각화해서 보면, 성능향상이 0.96 정도까지 훨씬 잘된것을 볼 수 있다.
특히 FineTuning을 풀어준 순간부터 성능향상도가 많이 증가한것을 볼 수 있다.
Keras Callbacks
학습과정에 TensorBoard,Checkpoint 등의 앞선 글에서 소개했던 기능을 손쉽게 사용할 수 있다.
https://keras.io/api/callbacks/
Keras documentation: Callbacks API
Callbacks API A callback is an object that can perform actions at various stages of training (e.g. at the start or end of an epoch, before or after a single batch, etc). You can use callbacks to: Write TensorBoard logs after every batch of training to moni
keras.io
위 사이트에서 보다 자세한 정보를 볼 수 있다.
'Python > 인공지능' 카테고리의 다른 글
| 10_Text Detection(문자감지) (0) | 2022.03.26 |
|---|---|
| 09_순환신경망 RNN (0) | 2022.03.19 |
| 06_CNN ILSVRC,CNN모델들 (0) | 2022.03.18 |
| 05_CNN 기초 (0) | 2022.03.18 |
| 04_오토인코더 (0) | 2022.03.18 |