
컴퓨터 비전에는 몇몇 어려운 점이 있다.
컴퓨터가 결국 이미지를 볼때는 0~255로 이루어진 숫자값을 가지고 이미지를 보게 된다.
사람은 이를 색으로 인지하고 있다.
즉, 컴퓨터가 이런 숫자 매트릭스로 되어있는 것만보고 의미를 부여해야하는데 이는 쉽지 않다. 저차원적 특징에서 고차원적 정보를 추출하는게 어렵기 때문에, 컴퓨터 비전으로 보는것은 어렵다!
특히 같은 공간에서 같은 대상을 찍어도 밝기에 따라서 픽셀을 완전 달라질 수 있다. 좀 더 생각하자면 배경과 고양이가 비슷한 색이어도 컴퓨터가 보기에는 마찬가지이다. 즉, 밝기, 변형, 가려짐, 배경등의 요소에 의해 영상인식의 난이도는 점점 올라가게 된다.
Handcrafed Feature
사람이 정한 특징 예를들어 줄무늬를 인식하는 필터를 사용해서 고양이를 검색한다. 즉, 줄무늬가 없는 고양이를 감지할때 정확도가 많이 떨어지게 된다.
End-To-end learning
끝과 끝 데이터만 넣어주고 딥러닝 모델에 모든걸 맡긴다. 정말 많은 분류데이터가 필요하지만 컴퓨터가 스스로 학습하게 만들어준다!
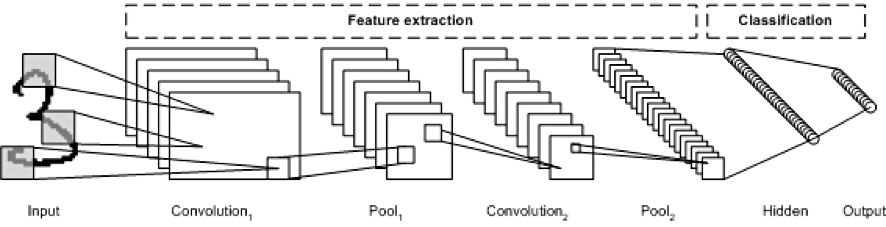
CNN(컨볼루션 신경망)
이미지 분야를 다루기에 최적화된 인공신경망 구조
컨볼루션층,풀링층으로 구성되어있다.
컨볼루션은 합성곱이다! 아마 공업수학을 들어봤다면 알 것인데, 모른다면 우선 하나의 연산이라는것만 알고 있자. 마치 곱하기와 같은 수학 연산중 하나라고 생각하면 된다.
이 컨볼루션 연산을 이용하여 이미지를 처리하면, 컨볼루션 커널에 따라 원본 이미지의 모서리를 추출하거나, 이미지를 명확하게 만드는등의 작업을 할 수 있다. 즉, 원본이미지에서 명확히 드러나지 않던 특징을 추출하는것이 가능하게 된다.
그렇다면 풀링이 뭔지 알아보자. 풀링층을 차원을 축소하는 연산이다.
최대값풀링,평균값풀링, 최소값 풀링이 있다.

풀링을 사용하면 차원축소가되는 효과가 있어 연산량을 감소시킬 수 있고, 이미지의 가장 강한 특징만을 추출하는 특징 선별 효과가 있다. 예를들어 모서리가 추출된 상태에서 최대값 풀링을 수행하게 되면 가장 강한 부분만 살아남게 될 것이다.
컨볼루션층의 결과는 결국 [w,h,k]로 출력되게 된다.
h는 출력이미지의 세로길이,
k는 컨볼루션 필터개수로 우리가 설정할 수 있는 값이다!
결국 이렇게 추출된 맵들은 이전글에서 설명한 ANN구조인 완전 연결층의 인풋으로 들어가서 Softmax분류를 수행하게 되는 것이다.
# -*- coding: utf-8 -*-
# Convolutional Neural Networks(CNN)을 이용한 MNIST 분류기(Classifier) - Keras API를 이용한 구현
import tensorflow as tf
# MNIST 데이터를 다운로드 합니다.
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 이미지들을 float32 데이터 타입으로 변경합니다.
x_train, x_test = x_train.astype('float32'), x_test.astype('float32')
# 28*28 형태의 이미지를 784차원으로 flattening 합니다.
x_train, x_test = x_train.reshape([-1, 784]), x_test.reshape([-1, 784])
# [0, 255] 사이의 값을 [0, 1]사이의 값으로 Normalize합니다.
x_train, x_test = x_train / 255., x_test / 255.
# 레이블 데이터에 one-hot encoding을 적용합니다.
y_train, y_test = tf.one_hot(y_train, depth=10), tf.one_hot(y_test, depth=10)
# tf.data API를 이용해서 데이터를 섞고 batch 형태로 가져옵니다.
train_data = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_data = train_data.repeat().shuffle(60000).batch(50)
train_data_iter = iter(train_data)
# tf.keras.Model을 이용해서 CNN 모델을 정의합니다.
class CNN(tf.keras.Model):
def __init__(self):
super(CNN, self).__init__()
# 첫번째 Convolution Layer
# 5x5 Kernel Size를 가진 32개의 Filter를 적용합니다.
self.conv_layer_1 = tf.keras.layers.Conv2D(filters=32, kernel_size=5, strides=1, padding='same', activation='relu')
self.pool_layer_1 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=2)
# 두번째 Convolutional Layer
# 5x5 Kernel Size를 가진 64개의 Filter를 적용합니다.
self.conv_layer_2 = tf.keras.layers.Conv2D(filters=64, kernel_size=5, strides=1, padding='same', activation='relu')
self.pool_layer_2 = tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=2)
# Fully Connected Layer
# 7x7 크기를 가진 64개의 activation map을 1024개의 특징들로 변환합니다.
self.flatten_layer = tf.keras.layers.Flatten()
self.fc_layer_1 = tf.keras.layers.Dense(1024, activation='relu')
# Output Layer
# 1024개의 특징들(feature)을 10개의 클래스-one-hot encoding으로 표현된 숫자 0~9-로 변환합니다.
self.output_layer = tf.keras.layers.Dense(10, activation=None)
def call(self, x):
# MNIST 데이터를 3차원 형태로 reshape합니다. MNIST 데이터는 grayscale 이미지기 때문에 3번째차원(컬러채널)의 값은 1입니다.
x_image = tf.reshape(x, [-1, 28, 28, 1])
# 28x28x1 -> 28x28x32
h_conv1 = self.conv_layer_1(x_image)
# 28x28x32 -> 14x14x32
h_pool1 = self.pool_layer_1(h_conv1)
# 14x14x32 -> 14x14x64
h_conv2 = self.conv_layer_2(h_pool1)
# 14x14x64 -> 7x7x64
h_pool2 = self.pool_layer_2(h_conv2)
# 7x7x64(3136) -> 1024
h_pool2_flat = self.flatten_layer(h_pool2)
h_fc1 = self.fc_layer_1(h_pool2_flat)
# 1024 -> 10
logits = self.output_layer(h_fc1)
y_pred = tf.nn.softmax(logits)
return y_pred, logits
# cross-entropy 손실 함수를 정의합니다.
@tf.function
def cross_entropy_loss(logits, y):
return tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y))
# 최적화를 위한 Adam 옵티마이저를 정의합니다.
optimizer = tf.optimizers.Adam(1e-4)
# 최적화를 위한 function을 정의합니다.
@tf.function
def train_step(model, x, y):
with tf.GradientTape() as tape:
y_pred, logits = model(x)
loss = cross_entropy_loss(logits, y)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# 모델의 정확도를 출력하는 함수를 정의합니다.
@tf.function
def compute_accuracy(y_pred, y):
correct_prediction = tf.equal(tf.argmax(y_pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
return accuracy
# Convolutional Neural Networks(CNN) 모델을 선언합니다.
CNN_model = CNN()
# 10000 Step만큼 최적화를 수행합니다.
for i in range(10000):
# 50개씩 MNIST 데이터를 불러옵니다.
batch_x, batch_y = next(train_data_iter)
# 100 Step마다 training 데이터셋에 대한 정확도를 출력합니다.
if i % 100 == 0:
train_accuracy = compute_accuracy(CNN_model(batch_x)[0], batch_y)
print("반복(Epoch): %d, 트레이닝 데이터 정확도: %f" % (i, train_accuracy))
# 옵티마이저를 실행해 파라미터를 한스텝 업데이트합니다.
train_step(CNN_model, batch_x, batch_y)
# 학습이 끝나면 학습된 모델의 정확도를 출력합니다.
print("정확도(Accuracy): %f" % compute_accuracy(CNN_model(x_test)[0], y_test))
중요한 부분은 CNN을 정의한 부분이다.
MNIST데이터를 인풋으로 받아 5 * 5 크기의 Kernel Size를 가진 32개의 Filter를 적용한다.
그이후 call 함수에서 풀링과정이 진행되는것을 알 수 있다.
이때 logit값을 반환하는 이유는 그 아래에 cross-entropy손실함수를 정의하기 위해서 필요하다! 그아래부터는 최적화를 위한 Adam 옵티마이저를 정의하고 정확도출력을 하는 함수를 정의해준 후에 모델을 선언하고 학습을 시킨 후에 정확도를 확인해보는 과정을 거치게 된다.

출력이 잘 됨을 알 수 있다.
Regularization
오버피팅을 방지할 수 있도록 만들어주는 기법들이다.

트레이닝을 너무 과하게 하면 오버피팅이 날 수 있다. 마치 답안을 외워서 시험을 보는것과 같이, 너무 트레이닝을 많이 하면 오버피팅이 일어나는데 DropOut은 학습과정에서 일부 노드를 사용하지 않는 형태로 만들어서 오버피팅을 방지할 수 있게 만들어주는 Regularization 기법이다.

Training Data에 대해서는 오버피팅을 방지하기위해 드롭아웃을 수행하지만, TestData에 대해서는 Dropout을 수행하지 않는다! Tensorflow 라이브러리에서 설정하기 편하게 설정이 잘 되어 있다.
https://www.tensorflow.org/api_docs/python/tf/nn/dropout
tf.nn.dropout | TensorFlow Core v2.8.0
Computes dropout: randomly sets elements to zero to prevent overfitting.
www.tensorflow.org
위에서 자세한 설정사항을 확인할 수 있다.
CIFAR-10 Data
MNIST데이터가 아닌 CIFAR데이터 셋을 이용해보자.
https://www.cs.toronto.edu/~kriz/cifar.html
CIFAR-10 and CIFAR-100 datasets
< Back to Alex Krizhevsky's home page The CIFAR-10 and CIFAR-100 are labeled subsets of the 80 million tiny images dataset. They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. The CIFAR-10 dataset The CIFAR-10 dataset consists of 60000
www.cs.toronto.edu
위에서 자세한 정보를 볼 수 있다.
CIFAR-10 Data는 10개의 클래스, 5만개의 traning, 1만개의 test이미지, 32 * 32의 이미지를 지원해준다.
# -*- coding: utf-8 -*-
"""
CIFAR-10 Convolutional Neural Networks(CNN) 예제 - Keras API를 이용한 구현
"""
import tensorflow as tf
# CIFAR-10 데이터를 다운로드하고 데이터를 불러옵니다.
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
# 이미지들을 float32 데이터 타입으로 변경합니다.
x_train, x_test = x_train.astype('float32'), x_test.astype('float32')
# [0, 255] 사이의 값을 [0, 1]사이의 값으로 Normalize합니다.
x_train, x_test = x_train / 255., x_test / 255.
# scalar 형태의 레이블(0~9)을 One-hot Encoding 형태로 변환합니다.
y_train_one_hot = tf.squeeze(tf.one_hot(y_train, 10), axis=1)
y_test_one_hot = tf.squeeze(tf.one_hot(y_test, 10), axis=1)
# tf.data API를 이용해서 데이터를 섞고 batch 형태로 가져옵니다.
train_data = tf.data.Dataset.from_tensor_slices((x_train, y_train_one_hot))
train_data = train_data.repeat().shuffle(50000).batch(128)
train_data_iter = iter(train_data)
test_data = tf.data.Dataset.from_tensor_slices((x_test, y_test_one_hot))
test_data = test_data.batch(1000)
test_data_iter = iter(test_data)
MNIST데이터를 가져올때와 유사하다.
데이터를 가져온 후에 tf.squeeze를 이용해서 더미 디멘션을 없애준다.
[1,2,1,3,1,1,1] 이란 차원 요소가 있다면
[2,3] 처럼 불필요한 1차원을 없애준다.
tf.expand_dims를 이용하면 반대로 차원을 만들 수 도 있다. 보통 batch 차원을 만들기 위해서 만들어준다.
결과를 테스트할땐 이미지를 한개씩 넣는경우가 많기에 더미디멘션을 1차원으로 만들어서 값을 넣어주는 것이다!
# tf.keras.Model을 이용해서 CNN 모델을 정의합니다.
class CNN(tf.keras.Model):
def __init__(self):
super(CNN, self).__init__()
# 첫번째 convolutional layer - 하나의 RGB 이미지를 64개의 특징들(feature)으로 맵핑(mapping)합니다.
self.conv_layer_1 = tf.keras.layers.Conv2D(filters=64, kernel_size=5, strides=1, padding='same', activation='relu')
self.pool_layer_1 = tf.keras.layers.MaxPool2D(pool_size=(3, 3), strides=2)
# 두번째 convolutional layer - 64개의 특징들(feature)을 64개의 특징들(feature)로 맵핑(mapping)합니다.
self.conv_layer_2 = tf.keras.layers.Conv2D(filters=64, kernel_size=5, strides=1, padding='same', activation='relu')
self.pool_layer_2 = tf.keras.layers.MaxPool2D(pool_size=(3, 3), strides=2)
# 세번째 convolutional layer
self.conv_layer_3 = tf.keras.layers.Conv2D(filters=128, kernel_size=3, strides=1, padding='same', activation='relu')
# 네번째 convolutional layer
self.conv_layer_4 = tf.keras.layers.Conv2D(filters=128, kernel_size=3, strides=1, padding='same', activation='relu')
# 다섯번째 convolutional layer
self.conv_layer_5 = tf.keras.layers.Conv2D(filters=128, kernel_size=3, strides=1, padding='same', activation='relu')
# Fully Connected Layer 1 - 2번의 downsampling 이후에, 우리의 32x32 이미지는 8x8x128 특징맵(feature map)이 됩니다.
# 이를 384개의 특징들로 맵핑(mapping)합니다.
self.flatten_layer = tf.keras.layers.Flatten()
self.fc_layer_1 = tf.keras.layers.Dense(384, activation='relu')
self.dropout = tf.keras.layers.Dropout(0.2)
# Fully Connected Layer 2 - 384개의 특징들(feature)을 10개의 클래스-airplane, automobile, bird...-로 맵핑(mapsping)합니다.
self.output_layer = tf.keras.layers.Dense(10, activation=None)
def call(self, x, is_training):
# 입력 이미지
h_conv1 = self.conv_layer_1(x)
h_pool1 = self.pool_layer_1(h_conv1)
h_conv2 = self.conv_layer_2(h_pool1)
h_pool2 = self.pool_layer_2(h_conv2)
h_conv3 = self.conv_layer_3(h_pool2)
h_conv4 = self.conv_layer_4(h_conv3)
h_conv5 = self.conv_layer_5(h_conv4)
h_conv5_flat = self.flatten_layer(h_conv5)
h_fc1 = self.fc_layer_1(h_conv5_flat)
# Dropout - 모델의 복잡도를 컨트롤합니다. 특징들의 co-adaptation을 방지합니다.
h_fc1_drop = self.dropout(h_fc1, training=is_training)
logits = self.output_layer(h_fc1_drop)
y_pred = tf.nn.softmax(logits)
return y_pred, logits
# cross-entropy 손실 함수를 정의합니다.
@tf.function
def cross_entropy_loss(logits, y):
return tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y))
# 최적화를 위한 RMSprop 옵티마이저를 정의합니다.
optimizer = tf.optimizers.RMSprop(1e-3)
# 최적화를 위한 function을 정의합니다.
@tf.function
def train_step(model, x, y, is_training):
with tf.GradientTape() as tape:
y_pred, logits = model(x, is_training)
loss = cross_entropy_loss(logits, y)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# 모델의 정확도를 출력하는 함수를 정의합니다.
@tf.function
def compute_accuracy(y_pred, y):
correct_prediction = tf.equal(tf.argmax(y_pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
return accuracy
# Convolutional Neural Networks(CNN) 모델을 선언합니다.
CNN_model = CNN()
# 10000 Step만큼 최적화를 수행합니다.
for i in range(10000):
batch_x, batch_y = next(train_data_iter)
# 100 Step마다 training 데이터셋에 대한 정확도와 loss를 출력합니다.
if i % 100 == 0:
train_accuracy = compute_accuracy(CNN_model(batch_x, False)[0], batch_y)
loss_print = cross_entropy_loss(CNN_model(batch_x, False)[1], batch_y)
print("반복(Epoch): %d, 트레이닝 데이터 정확도: %f, 손실 함수(loss): %f" % (i, train_accuracy, loss_print))
# 20% 확률의 Dropout을 이용해서 학습을 진행합니다.
train_step(CNN_model, batch_x, batch_y, True)
# 학습이 끝나면 테스트 데이터(10000개)에 대한 정확도를 출력합니다.
test_accuracy = 0.0
for i in range(10):
test_batch_x, test_batch_y = next(test_data_iter)
test_accuracy = test_accuracy + compute_accuracy(CNN_model(test_batch_x, False)[0], test_batch_y).numpy()
test_accuracy = test_accuracy / 10
print("테스트 데이터 정확도: %f" % test_accuracy)그 다음 구성은 거의 유사하다!
차이가 있다면 중간에 self.dropout 부분이 있는데 tf.keras.layers.Dropout(0.2)를 작성해서 20% 는 랜덤적으로 가져가지 않게 설정해 두었다.
'Python > 인공지능' 카테고리의 다른 글
| 08_개,고양이 구분 인공지능 구현 (0) | 2022.03.18 |
|---|---|
| 06_CNN ILSVRC,CNN모델들 (0) | 2022.03.18 |
| 04_오토인코더 (0) | 2022.03.18 |
| 03_다중 퍼셉트론 MLP,인공신경망 (0) | 2022.03.18 |
| 02_ Softmax Regression을 활용한 MNIST숫자분류기 구현 (0) | 2022.03.13 |