
만약 예제 코드가 아닌 복잡한 실제 문제를 해결하다보면 짧게는 몇시간부터 몇일에 거쳐 학습을 해야할 경우가 생긴다. 그래서 중간중간 파라미터를 저장하고 이어 학습을 진행해주는 과정이 필요한데,
tf.train.CheckpointManager API를 통하여 이를 저장할 수 있다.
1. tf.train.Checkpoint클래스의 인자값으로 tf.kears.Model 인스턴스와 전역 반복횟수를 선언해준다.
ckpt = tf.train.Checkpoint(step=tf.Variable(0),model=CNN_model)
2. tf.train.CheckpointManager에 인자값으로 ㅅ너언한 tf.train.Checkpoint 인스턴스와 중간 파라미터를 저장할 경로를 설정한다.
ckpt_manager = tf.train.CheckpointManager(ckpt,directtory=SAVER_DIR,max_to_keep=5)
3. 파라미터를 저장하고자 하는 시점에 해당 시점의전역 반복횟수를 인자값으로 선언한 tf.train.CheckpointManager의 save메소드를 호출합니다.
ckpt_manager.save(checkpoint_number = ckpt.step)
4. tf.train.Checkpoint의 전역 반복 횟수 값(ckpt.step)을 매 반복마다 1씩 증가시킨다.
ckpt.step.assign_add(1)
불러오는법은 아래와 같다.
1.tf.train.latest_checkpoint의 인자값으로 파라미터가 저장된 폴더 경로를 지정해서 가장 최근의 체크포인트 파일의 경로를 가져온다.
latest_ckpt = tf.train.latest_checkpoint(SAVER_DIR)
2.선언한 tf.train.CheckpointManger의 resotre함수의 인자값으로 파일경로를 지정해서 복원한다.
ckpt.restore(latest_ckpt)
#이전 CNN과 같음
# tf.train.CheckpointManager를 이용해서 파라미터를 저장합니다.
SAVER_DIR = "./model"
ckpt = tf.train.Checkpoint(step=tf.Variable(0), model=CNN_model)
ckpt_manager = tf.train.CheckpointManager(
ckpt, directory=SAVER_DIR, max_to_keep=5)
latest_ckpt = tf.train.latest_checkpoint(SAVER_DIR)
# 만약 저장된 모델과 파라미터가 있으면 이를 불러오고 (Restore)
# Restored 모델을 이용해서 테스트 데이터에 대한 정확도를 출력하고 프로그램을 종료합니다.
if latest_ckpt:
ckpt.restore(latest_ckpt)
print("테스트 데이터 정확도 (Restored) : %f" % compute_accuracy(CNN_model(x_test)[0], y_test))
exit()
# 10000 Step만큼 최적화를 수행합니다.
while int(ckpt.step) < (10000 + 1):
# 50개씩 MNIST 데이터를 불러옵니다.
batch_x, batch_y = next(train_data_iter)
# 100 Step마다 training 데이터셋에 대한 정확도를 출력하고 tf.train.CheckpointManager를 이용해서 파라미터를 저장합니다.
if ckpt.step % 100 == 0:
ckpt_manager.save(checkpoint_number=ckpt.step)
train_accuracy = compute_accuracy(CNN_model(batch_x)[0], batch_y)
print("반복(Epoch): %d, 트레이닝 데이터 정확도: %f" % (ckpt.step, train_accuracy))
# 옵티마이저를 실행해 파라미터를 한스텝 업데이트합니다.
train_step(CNN_model, batch_x, batch_y)
ckpt.step.assign_add(1)
# 학습이 끝나면 테스트 데이터에 대한 정확도를 출력합니다.
print("정확도(Accuracy): %f" % compute_accuracy(CNN_model(x_test)[0], y_test))
Checkpoint Manager를 사용하는 부분을 보면 위에서 설명한 과정에 따라서 진행되는것을 볼 수 있다.
실제 코드를 동작시켜보면 파일로 학습된 내용들이 일정 주기마다 저장되는것을 확인할 수 있다.
TensorBoard
터미널 로그등을 이용해서 학습과정을 볼 경우, 한눈에 학습과정의 문제점을 확인하기가 어렵다. 그렇기 때문에 TensorFlow에서는 학습과정 시각화를 위한 TensorBoard라는 기능을 제공한다! 그래프 형태로 봐서 좀 더 직관적으로 볼 수 있는 기능이다.
tf.summary.scalar : scalar 형태의 로그를 저장한다. ( 정확도 등 )
tf.summary.histogram : histogram 형태의 로그를 저장한다.
tf.summary.image : 이미지 형태의 로그를 저장한다.
위는 많이 자주 쓰이는 TensorFlow에서 제공하는 것들이다.
텐서보드 로그를 저장하는 방법부터 보자.
1. 인자값으로 텐서보드 로그파일을 저장할 경로를 지정
summary_writer = tf.summary.create_file_writer('./tensorboard_log')
2. 요약 정보를 남기고 싶은 값을 Writer scope 내에서 tf.summary.*API로 추가
with summary_writer.as_default():
tf.summary.scalar('loss',loss,step-optimizer.iterations)
위는 로스값을 정보로 남긴 경우이다.
파일을 저장한 위칠를 잡고
tensorboard --logdir-path/to/log-directory
localhost:6006을 보면 그래프 형태로 로그가 저장된걸 알 수 있다.
# 텐서보드 summary 정보들을 저장할 폴더 경로를 설정하고 FileWriter를 선언합니다.
train_summary_writer = tf.summary.create_file_writer('./tensorboard_log/train')
test_summary_writer = tf.summary.create_file_writer('./tensorboard_log/test')그후 예제 코드에 FileWriter를 설정해주고
# 최적화를 위한 function을 정의합니다.
@tf.function
def train_step(model, x, y):
with tf.GradientTape() as tape:
y_pred, logits = model(x)
loss = cross_entropy_loss(logits, y)
# 매 step마다 tf.summary.scalar, tf.summary.image 텐서보드 로그를 기록합니다.
with train_summary_writer.as_default():
tf.summary.scalar('loss', loss, step=optimizer.iterations)
x_image = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('training image', x_image, max_outputs=10, step=optimizer.iterations)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# 모델의 정확도를 출력하는 함수를 정의합니다.
@tf.function
def compute_accuracy(y_pred, y, summary_writer):
correct_prediction = tf.equal(tf.argmax(y_pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with summary_writer.as_default():
tf.summary.scalar('accuracy', accuracy, step=optimizer.iterations)
return accuracy
# Convolutional Neural Networks(CNN) 모델을 선언합니다.
CNN_model = CNN()
# 10000 Step만큼 최적화를 수행합니다.
for i in range(10000):
# 50개씩 MNIST 데이터를 불러옵니다.
batch_x, batch_y = next(train_data_iter)
# 100 Step마다 training 데이터셋에 대한 정확도를 출력합니다.
if i % 100 == 0:
train_accuracy = compute_accuracy(CNN_model(batch_x)[0], batch_y, train_summary_writer)
print("반복(Epoch): %d, 트레이닝 데이터 정확도: %f" % (i, train_accuracy))
# 옵티마이저를 실행해 파라미터를 한스텝 업데이트합니다.
train_step(CNN_model, batch_x, batch_y)
# 학습이 끝나면 학습된 모델의 정확도를 출력합니다.
print("정확도(Accuracy): %f" % compute_accuracy(CNN_model(x_test)[0], y_test, test_summary_writer))
위코드의 train_step에서 함수가 작동할때 traing image이름으로 저장되는것을 알 수 있다. 50개는 너무 많기에 max_outputs를 10개로 둬서 10개만 출력하게 두었다
로직을 보면 100번 반복할때마다 정확도를 출력하는데, 이 값또한 그래프로 넣어준것을 알 수 있다.
ResNet
ResNet은 기존 GoogleLeNet등에 비해 엄청 깊은 레이어를 가지고 있는 점이 특징이다. 레이어가 깊어질수록 성능이 떨어지는 현상이 관찰되는데, 이는 training error에서도 발생하기때문에 overfitting 문제가 아님을 알 수 있을 것이다.
저자들은 레이어가 깊으면 학습하기가 더 어렵기 때문에 성능이 떨어졌다고 가설을 세웠었다. 그래서 저자들은 레이어를 깊게하면서 학습의 난이도를 낮추는 방식을 택했다!

X identity를 추가해주면 되기 때문에 추가하는것은 그렇게 난이도가 높지 않다.
Fine-Tuning(Transfer Learning)
이미 학습된 neural Networks의 파라미터를 새로운 일에 맞게 다시 미세조정 하는것이다.
다른 말로는 Transfer Learning(전이학습)이라고도 한다.
만약 호랑이를 구분하는 파라미터가 잘되어있다면 이를 살짝 조정하여 고양이를 분류하는데 사용하는데 적용하게 할 수 있는 것이다.
어디까지 학습대상으로 삼을지 결정해서 Fine-Tuning을 진행하면 된다.
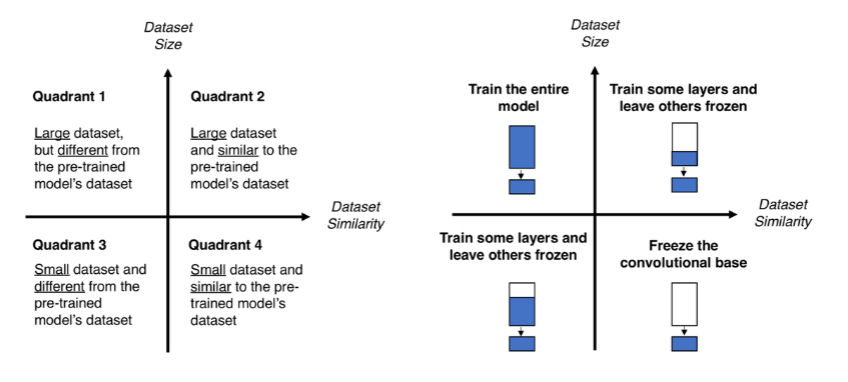
보통 위와같은 의사결정 단계를 거쳐서 결정되게 된다.
이전 글에서 TensorFlow를 사용하여 딥러닝을 구현할때 초보자용과 전문가용이 있다고 했었는데, 한번 초보자용 스타일의 방식으로 트레이닝을 해보도록 하자. 참고로 앞의 글의 방식은 experts 즉 전문가용 방식이었다.
https://colab.research.google.com/drive/1bdyNIJPKVQZG7Y-rlrgQ8gBKTH75xI_n?usp=sharing
beginner_style_implementation.ipynb
Colaboratory notebook
colab.research.google.com
위 코랩에서 한번 실습을 해보도록 하자. 위 코드는 tesorflow에서 제공해주는 공식 가이드이다.
'Python > 백준' 카테고리의 다른 글
| 1260_bfs와dfs (0) | 2022.03.25 |
|---|---|
| 2629_양팔저울(파이썬,쉬운풀이) (0) | 2022.03.20 |
| 1520_내리막길 (0) | 2022.03.16 |
| 11049_행렬 곱셈 순서 (파이썬,설명) (0) | 2022.03.14 |
| 11066_파일 합치기 ( 파이썬, 설명위주 ) (0) | 2022.03.13 |