
이번에는 인공신경망을 low레벨에서 직접구현 해보았다.
만약에 AND게이트를 구현한다고 생각해보자. 우리는 퍼셉트론이라는 개념을 알아야 한다.
class perceptron_for_GATE: #GATE만들기위한 퍼셉트론
def __init__(self,w):
self.w = w
def output(self,x):
tmp = np.dot(self.w,np.append(1,x))
result = 1.0*(tmp>0)
return result퍼셉트론은 위와같은 구조로 만들 수 있다.
w_and = np.array([-1.2,1,1]) #AND GATE
and_gate = perceptron_for_GATE(w_and)
w_or = np.array([-0.8,1,1]) # OR GATE
or_gate = perceptron_for_GATE(w_or)
w_nand = np.array([1.2,-1,-1]) #NAND GATE
nand_gate = perceptron_for_GATE(w_nand)만약 w값들을 적당히 조절할 수 있다면 AND,OR,NAND게이트를 구현하는것도 쉽다.
하지만 XOR그래프를 생각해 보자.

예를들어 위와같은 경우는 직선으로 구분할 수 없다. 그렇다면 어떻게 위와같은 경우를 구분지을 수 있을까?
만약 논리게이트를 조금 공부한 사람들은 알겠지만, XOR게이트같은 경우는 OR,NAND,AND게이트로 구현할 수 있다. 바로 아래 사진처럼 말이다.
위와같이 게이트들을 연결한 것처럼 퍼셉트론들을 연결해서 XOR게이트를 구현해 볼 수 있다.
이런식으로 층을 붙여서 사용한다면, 우리는 결국 이 문제를 풀기위한 적절한 W값들을 구하면 된다.
그리고 이 W들을 구하기위해서 개개별로 수식을 구하는건 굉장히 어렵기에, 이전에 공부하였던 경사하강법을 통해 구현하면 우리가 풀고자 하는 문제에 해당하는 W들을 구할 수 있다.
위는 만약 입력,은닉,출력 층이 다음과 같이 주어지고 w값들이 주어졌다면 예측값을 구하는 방법이다.
x1,x2들과 w들을 계산해서 (행렬연산으로 하면 쉽다) z들을 구하고 이를 활성화 함수를 거쳐거 가공한다.
활성화함수를 거쳐서 값들을 0~1사이로 바꾸거나 하는 가공이 가능한데 sigmoid,relu 등등의 함수가 존재한다. 필자는 sigmoid 함수를 사용하여 가공하였다.
이후 수식을 통해서 W를 업데이트하는 과정을 아래와 같다.
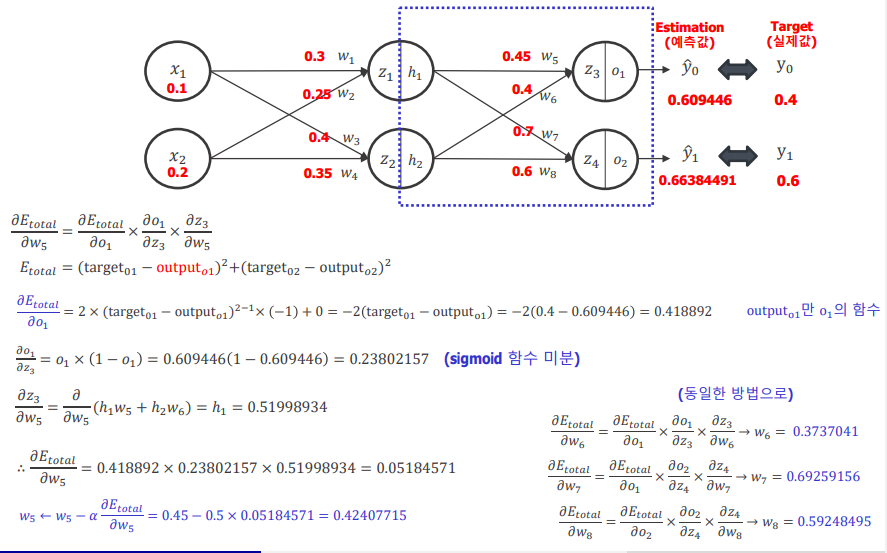
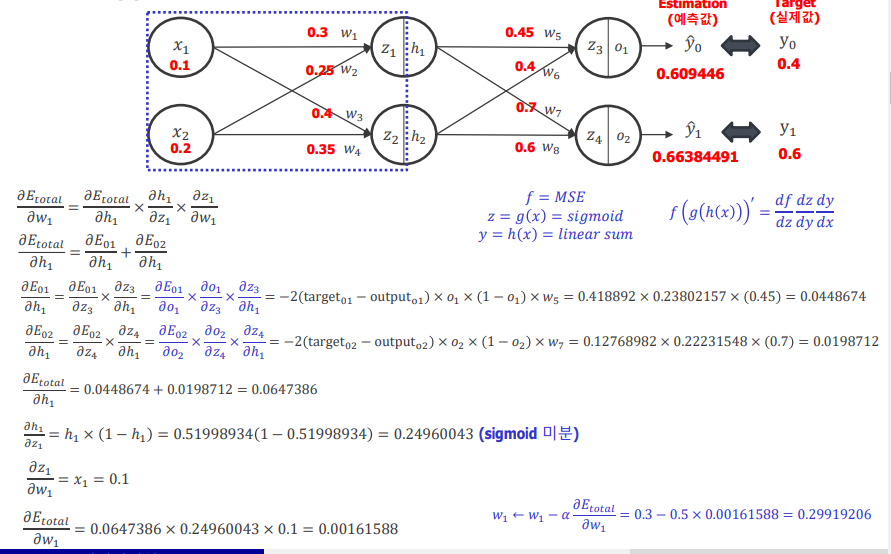
수식이 어렵지만 간단하게 생각해보면 W들의 한개를 업데이트할때 경사하강법을 사용하던것을 확장해서 사용했다고 생각하면 된다.
그렇다면 이 직접 구현한 인공지능을 한번 실행해보자.
데이터는 해당 데이터를 사용하였다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
class perceptron: #perceptron 클래스 구현
def __init__(self,w):
self.w = w
def output(self,x):
return np.dot(np.append(x,1),self.w)
def sigmoid(x): #시그모이드 함수
return 1/(1+np.exp(-x))
def one_hot_encoding(array,size):
lst = [] #one_hot_encoding 과정
for i in array:
tmp = [0] * size
tmp[i-1] +=1
lst.append(tmp)
return np.array(lst)
class Neural_Network: #2계층 신경망 구현
def __init__(self,hidden_layer_size,Input,Output,learning_rate,Test_set):
self.hidden_layer_size = hidden_layer_size #은닉층 노드 개수
self.Input_size = Input.shape[1] #입력층 사이즈
self.Output_size= Output.shape[1] #출력층 사이즈
self.X = Input #트레이닝 셋 입력
self.Y = Output #트레이닝 셋 출력(정답)
self.learning_rate = learning_rate #Learning rate
self.Create_Weight_Matrix() #W0,W1매트릭스 임의 생성
self.Test_set = Test_set #테스트셋 저장
def Create_Weight_Matrix(self): #Weight 를 만드는 함수
self.W0 = np.random.randn(self.Input_size+1, self.hidden_layer_size)
self.W1 = np.random.randn(self.hidden_layer_size+1, self.Output_size)
def Set_Hidden_layer_Node_size(self,size): #히든Node수 설정
self.hidden_layer_size = size
self.Create_Weight_Matrix()
def Check_Input_Output_size(self): #Input,Output 체크함수
print('Input 속성 수 ====>',self.Input_size)
print('Output 속성 수 ===>',self.Output_size)
def predict(self,x): #y예측 함수
INPUT_LAYER = perceptron(self.W0)
OUTPUT_LAYER = perceptron(self.W1)
self.sigmoid_input = sigmoid(INPUT_LAYER.output(x))
self.H = np.append(self.sigmoid_input,1)
return sigmoid(OUTPUT_LAYER.output(self.sigmoid_input))
def Back_propagation(self):
lr = self.learning_rate #Learning rate
for i in range(len(self.X)):
Y_pred = self.predict(self.X[i]) #Y 예측값
Input = np.append(self.X[i], 1) #입력층 + 1 추가
#역전파를 1단계부터 시행하면 W가 업데이트되어 2단계부터 시행
for j in range(self.Input_size + 1): # 역전파 2단계
for k in range(self.hidden_layer_size):
Etotal_h_diff = 0
for q in range(self.Output_size):
Etotal_h_diff += -2 * (self.Y[i][q] - Y_pred[q]) * Y_pred[q] * (1 - Y_pred[q]) * self.W1[k][q]
h_z_diff = self.H[k] * (1 - self.H[k])
z_w_diff = Input[j]
Etotal_w = Etotal_h_diff * h_z_diff * z_w_diff
self.W0[j][k] = self.W0[j][k] - lr * Etotal_w #W0업데이트
for j in range(self.hidden_layer_size+1): #역전파 1단계
for k in range(self.Output_size):
E_o_diff = -2 * ( self.Y[i][k] - Y_pred[k] )
o_z_diff = Y_pred[k] * (1 - Y_pred[k])
z_w_diff = self.H[j]
Etotal_w = E_o_diff * o_z_diff * z_w_diff
self.W1[j][k] = self.W1[j][k] - lr * Etotal_w #W1 업데이트
def train(self,epoch):
self.epoch = epoch #epoch 저장
self.MSEs = [] #MSE그래프를 그리기 위함
self.Accuaracys = [] #정확도 그래프를 그리기 위함
for i in range(epoch):
data = np.concatenate([self.X,self.Y],1) #셔플과정
np.random.shuffle(data) #매 에폭마다 섞어주는 과정
self.X,none,self.Y = np.hsplit(data,(self.Input_size,self.Input_size))
self.Back_propagation() #역전파 과정으로 W업데이트
tmp_mse=[] #정확도 계산
cnt = 0
for j in range(len(self.X)):
Y_pred = self.predict(self.X[j])
tmp_mse.append(np.mean((self.Y[j] - Y_pred)**2 ))
maxindex = np.argmax(self.predict(self.X[j])) #가장큰 index가져오기
tmp = np.array([0] * self.Output_size)
tmp[maxindex] = 1
if np.array_equal(tmp,self.Y[j]): #정답과 비교
cnt +=1
Accuracy = cnt / len(self.X)
self.Accuaracys.append(Accuracy)
test_X,none,test_Y = np.hsplit(Test_set,(self.Input_size,self.Input_size))
cnt = 0
for j in range(len(test_X)):
maxindex = np.argmax(self.predict(test_X[j]))
tmp = np.array([0] * self.Output_size)
tmp[maxindex] = 1
if np.array_equal(tmp,test_Y[j]):
cnt +=1
test_Accuracy = cnt / len(test_X)
MSE = np.mean(tmp_mse)
self.MSEs.append(MSE)
if i % 200 == 1:
print(f'EPOCH {i} ===> MSE : {MSE} , Accuracy : {Accuracy} , test_Accuracy : {test_Accuracy}')
current_path = os.path.dirname(os.path.abspath(__file__)) #파일 불러오기
raw_data = pd.read_csv('NN_data.csv',encoding='utf-8', engine = 'python')
NN_data = raw_data[['x0','x1','x2','y']].to_numpy() # x 데이터 받기
NN_data_size = len(NN_data)
X = raw_data[['x0','x1','x2']].to_numpy() # x 데이터 받기
Y = raw_data['y'].to_numpy() #y 데이터 받기
Y = one_hot_encoding(Y,3) #one Hot encoding 과정
NN_data = np.concatenate([X,Y],1)
np.random.shuffle(NN_data)
Traning_set = NN_data[:int(0.7*NN_data_size)]
Test_set = NN_data[int(0.7*NN_data_size):]
X,none,Y = np.hsplit(Traning_set,(3,3))
Network = Neural_Network(hidden_layer_size=3,Input=X,Output=Y,learning_rate=0.0001,Test_set=Test_set)
Network.Check_Input_Output_size()
Network.train(10000)
print('W0 :',Network.W0) #학습된 W0,W1 출력
print('W1 :',Network.W1)
plt.xlabel('Epoch')
plt.ylabel("MSE")
plt.grid()
plt.plot(range(len(Network.MSEs)),Network.MSEs,color='blue')
plt.show() #MSE 변화 출력
plt.xlabel('Epoch')
plt.ylabel("Accuracy")
plt.grid()
plt.plot(range(len(Network.Accuaracys)),Network.Accuaracys,color='blue')
plt.show() #정확도 변화 출력
클래스로 구현하였고, 차례대로 읽으면서 보면 수식을 그대로 옮겼다는걸 알 수 있다!
학습시키는데는 시간이 좀 걸리고, 완료되면 MSE와 정확도를 출력한다.
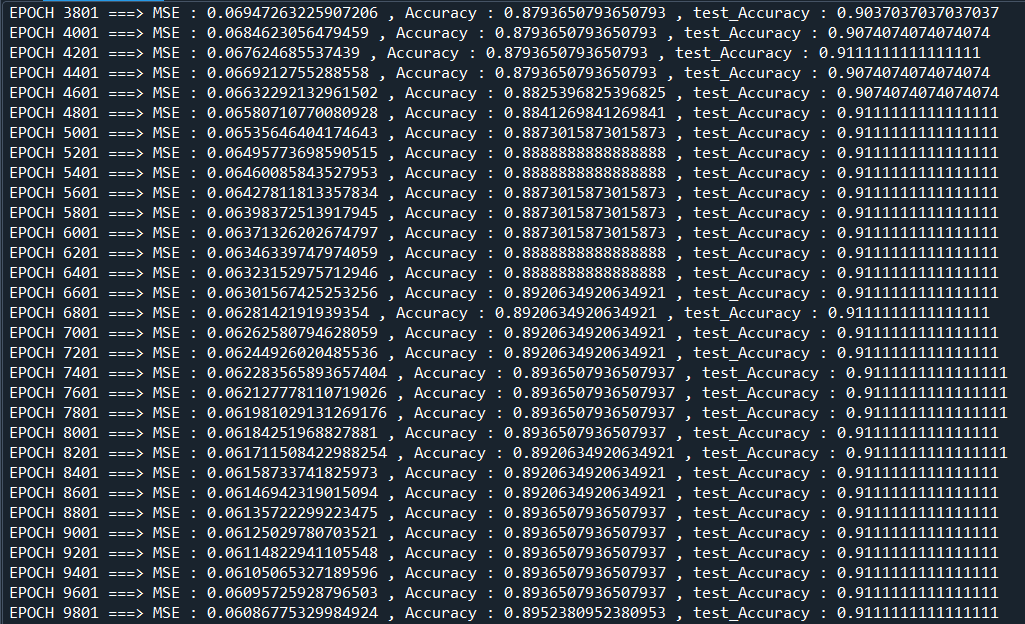
할때마다 조금씩 다르지만 대략 90%정도까지 학습이 되는것을 알 수 있다!
'Python > 인공지능' 카테고리의 다른 글
| Minist 데이터 활용 0,1,2 구분 인공지능 직접구현 (0) | 2022.06.19 |
|---|---|
| 클러스터링 K-Means 직접구현 (0) | 2022.06.11 |
| Training , Test 선택 가우시안 모델 구현하기 (0) | 2022.04.30 |
| 파이참에서 GPU사용! (0) | 2022.04.24 |
| 가우스 함수를 이용한 선형회귀 모델 직접구현 (0) | 2022.04.17 |